Eine Art, die Methoden der Statistik zu unterteilen, ist die, zwischen beschreibender und beurteilender Statistik zu unterscheiden.
Beschreibende Statistik umfasst alle Methoden, die das Ziel haben, vorhandene Meßgrößen so aufzubereiten, dass man Zusammenfassungen und grafische Darstellungen betrachten kann, und sich nicht durch endlose Zahlenkolonnen bewegen muss. Beurteilende Statistik umfasst die Methoden, die Aussagen dazu erlauben, ob eine aufgestellte Hypothese stimmt oder nicht, ob also eine Annahme, die man hat, durch die vorliegenden Meßwerte bestätigt oder widerlegt werden.
Ein großer Teil der Methoden aus dem Bereich der beschreibenden Statistik wird in der explorativen Datenanalyse (EDA) benutzt. EDA hat die Aufgabe, Daten aufzubereiten, wenn nur geringes oder kein Wissen über Zusammenhänge zwischen den Daten vorliegt. Man wendet EDA an, um sich hinterher die Frage zu stellen: „mit welchen Methoden machen wir weiter, um mehr zu verstehen?“
https://de.wikipedia.org/wiki/Explorative_Datenanalyse
Worauf es ankommt
Die Anfänge der explorativen Datenanalyse liegen über 150 Jahre zurück. Der Arzt John Snow fand durch Datenauswertung heraus, dass der Ursprung einer Cholera-Epidemie einer verseuchten Wasserpumpe zu verdanken ist, und die Krankheit somit nicht durch die Luft übertragen wird.
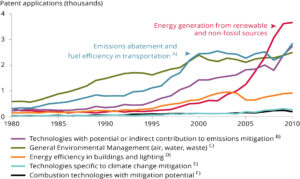
Jeder, der mit Meßwerten zu tun hat, lernt seitdem, dass es keinen Sinn macht, Zahlen im Rohzustand in größerer Menge zu betrachten und zu gleuben, man könnte sie auf diese Weise verstehen. Das klappt nicht. Selbst die alleinige Aufbereitung von Messgrößen zu statistischen Kennzahlen kann einen völlig falschen Eindruck vermitteln; man sollte – wo immer das möglich ist – Zahlen wirklich grafisch aufbereiten, um einen Überblick zu haben und Zusammenhänge zu verstehen.
Falls Sie das nicht glauben: lesen Sie über Anscombe’s Quartett nach.
https://en.wikipedia.org/wiki/Anscombe’s_quartet
Obwohl man also seit langem weiß, dass man sich durch (grafische) Zusammenfassungen einen Überblick verschaffen sollte, wenn man große Mengen an unbekannten uDaten verstehen will, hat sich die Vorgehensweise beim beruflichen Lesen von technischen Dokumenten nicht wesentlich geändert. Man liest, so wie man in der Freizeit einen Roman lesen würde.
Die Konsequenz ist, dass man nicht systematisch liest, was relevant ist, dass man vergessen hat, was in welchem Dokument steht, wenn es mehr als vielleicht 20 Dokumente sind, dass man nicht wieder findet, was man für wichtig gehalten hat, und dass es schwierig ist, viele Dokumente abzulegen, weil Ablagen in der Regel linear sind (d. h., nach einem Gesichtspunkt geordnet), in einer großen Dokumentkollektion aber die unterschiedlichsten Themengebiete enthalten sind.
Viele Dokumente so zu verwalten, dass man auch garantiert das wieder findet, was an Wissen darin enthalten ist, ist möglich, aber anspruchsvall. UND: suchen hilft nicht; man kann nur suchen, was man bereits kennt. Was machen Sie also mit dem Wissen, das Sie zwar haben (es ist in den Dokumenten enthalten), aber nicht kennen?