Home
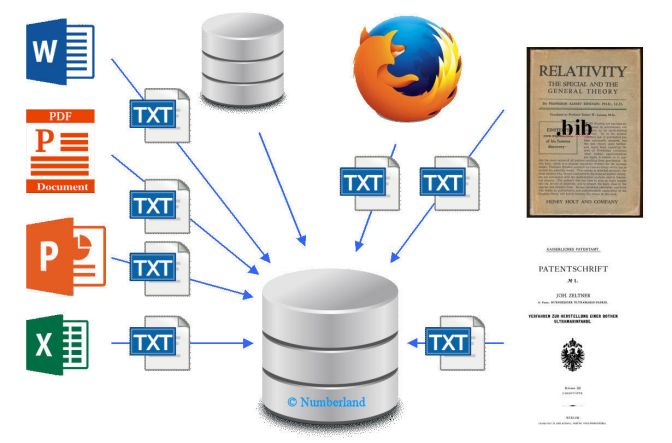
1. Acquisition: to perform a text mining project, a document collection has to be compiled. It can contain internal documents, websites, other databases, patents, scientific publications or a mixture of all these.
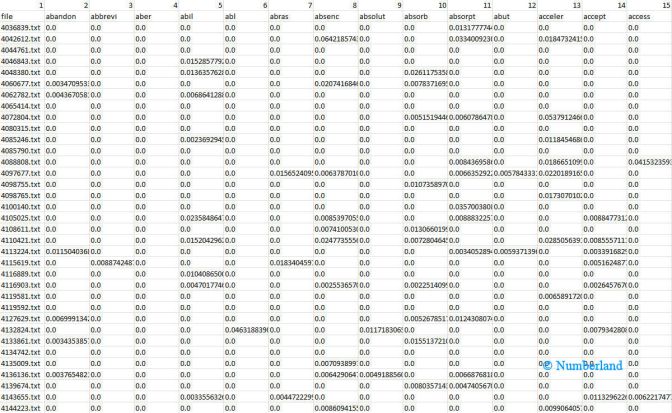
2. Preparation: a feature matrix from all documents has to be evaluated as a next step. To prepare a feature matrix, all documents are tokenized (=devided into single words), stop words are removed, and stemming is performed. Then a relative word frequency is calculated for each word in each document. Compiling this into a matrix (one row per document, one column per word, relative word frequency as cell value) results in the feature matrix.
3. Calculation: some part of the analysis, i. e. lists, some time series, the full text index, etc. can be calculated from the documents themselfes. To compute clusters, ngrams, associations or graphs the feature matrix from step two is used.
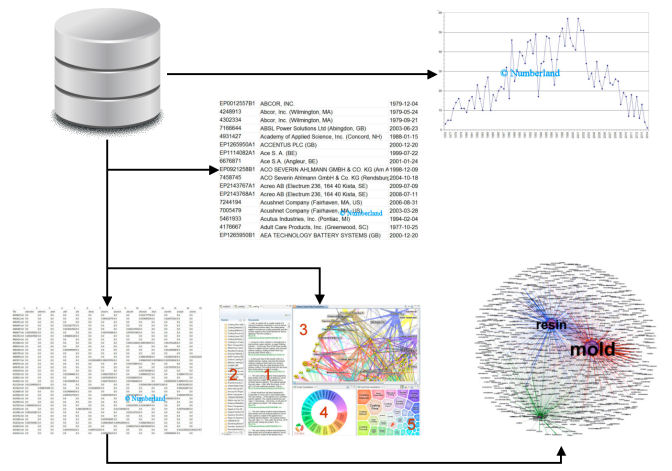
4. Presentation: calculation results are presented in step four - lists, graphics or networks.
