













Über Nacht zum Stand der Technik
Wir kombinieren die Text Mining Verfahren Clustern, Zusammenfassen, Assoziieren (=Korrelationen) und Visualisieren, um den Inhalt von Patenten, technisch-wissenschaftlichen Publkationen, Büchern oder internen Dokumenten bestmöglich zu erschließen und so IHREN Stand von Wissenschaft und Technik zu erfassen und darzustellen.
Immer wieder gibt es - besonders am Anfang – Stress in technischen oder strategischen Projekten (Produktentwicklung, geförderte Forschungsvorhaben, etc.), weil zu viel Zeit dafür benötigt wird, den aktuellen Stand der Technik aus Büchern, technisch-wissenschaftlich Publikationen oder Patenten zusammen zu tragen.Obwohl diese Aufgabe sehr wichtig ist, ist sie doch ausgesprochen lästig und zeitraubend, besonders dann, wenn es darum geht, sich in neue Themen einzuarbeiten und eine Orientierung zu bekommen.
Wir nehmen Ihnen die Schritte Beschaffen, Sichten, Sortieren und Ablegen ab, so dass Sie sich ganz auf das Verstehen und Entscheiden konzentrieren können.
Numberland verfügt neben eigenen Suchmaschinen auch über Technologien, mit deren Hilfe auch sehr umfangreiche Kollektionen von elektronischen Dokumenten beschafft, hinsichtlich inhaltlicher Schwerpunkte und Zusammenhänge analysiert und dynamisch sortiert werden können, so dass die Struktur sich automatisch an den Blickwinkel anpasst, unter dem Sie das Thema gerade sehen.
Wir finden zeitliche und inhaltliche Abhängigkeiten, thematische Schwerpunkte und sogar die Themen, von deren Existenz Sie bisher nichts wussten (und deswegen auch nicht suchen konnten).
Entsprechend vielfältig sind die Anwendungsszenarien; exemplarische Beispiele dafür sind:
- Wir stellen „ABC“ her: haben wir bereits alle Märkte berücksichtigt?
- Wer ist in welcher Situation auf welchem Markt tätig (für Forschungseinrichtungen sehr interessant, die sich Gedanken darüber machen, wer ihr neu entwickeltes Material, Bauteil, Herstellungs- oder Analytikverfahren wohl brauchen könnte)?
- Welches Patent, das zu meinem Geschäftsmodell passt, ist in der Zwischenzeit frei geworden?
- Wir möchten ein F&E-Vorhaben zum Thema „XYZ“ beginnen; wie ist der Stand von Forschung und Technik?
- TRIZ: welche Lösungen existieren bereits für ein bestimmtes Problem (bitte lesen Sie dazu auch unseren Artikel "Grammatikkenntnisse für die Produktentwicklung". Im Prinzip kombiniert man bestimmte Adjektive und/oder Verben, z. B. das Verb "absorbieren", mit Suchbegriffen über Werkstoffe oder Anwendungen um herauszufinden, welche Varianten dazu bereits existieren.
- Technologieroadmapping: wohin wollen wir uns entwickeln, in welchen Schritten gehen wir vor, und welche Technologien werden dazu wann benötigt?
- SWOT-Analyse: die SWOT-Analyse (engl. Akronym für Strengths (Stärken), Weaknesses (Schwächen), Opportunities (Chancen) und Threats (Gefahren)) ist ein Instrument der Strategischen Planung; sie dient der Positionsbestimmung und der Strategieentwicklung von Unternehmen und anderen Organisationen.
- Branchenstrukturanalyse nach dem Fünf-Kräfte-Modell von Michael Porter: wer sind meine Wettbewerber, was machen meine Kunden, meine Zulieferer, gibt es potentielle Mitbewerber oder Ersatzprodukte?
- Portfolioanalysen
- Untersuchungen zur Marktpositionierung
- Zielgruppenanalysen
- Businesspläne
Das übernehmen wir für Sie:
- Wir beschaffen technisch-wissenschaftliche Publikationen nach Ihren Stichworten in elektronischer Form,
- Wir beschaffen US- und EU-Patente in elektronischer Form nach Ihren Stichworten,
- Wir berücksichtigen bei Ihnen bereits vorhandene elektronische Dokumente,
- Wir analysieren die alle Texte im Zusammenhang und bestimmen Zeitverläufe, inhaltliche Schwerpunkte oder Zusammenhänge
- Wir finden auf Wunsch Themenkomplexe, deren Existenz Ihnen nicht bekannt ist, so dass Sie sie nicht suchen können
- Wir liefern alle bestellten Analysen zusammen mit den Originaldokumenten und einem Volltextindex incl. Suchmaske
Exemplarische Analysen für eine Kollektion von ca. 2000 Patenten haben wir Ihnen im folgenden Teil des Artikels zusammen gestellt. Alle Auswertungen sind als Beispiel zu verstehen, und können nahezu beliebig an Ihre Situation angepasst werden.
Interessiert?
Alles beginnt mit einem Dokument
Alles fängt mit einem elektronischen Dokument an (Buch, Publikation oder Patent), besser gesagt mit einer ganzen Kollektion solcher Dokumente, die nach von Ihnen vorgegebenen Stichworten gesammelt, oder aus Ihrem Bestand übernommen wurden.

Bild 1: Ein einzelnes Dokument, z. B. ein Patent
Mögliche Quellen dafür sind z. B.:
- Sie selbst,
- Universitäten und Forschungseinrichtungen weltweit (Numberland verfügt über eigene Suchmaschinen, die ständig ca. 16.000 Universitäten und Forschungseinrichtungen durchsuchen)
- Patentämter (z. B. EU- und US-Patentamt).
Folgende Dokumentformate sind möglich:
- MS-Office, Libreoffice, .pdf, .txt, .xml,
- Bildformate (.jpg, .gif, .png, .tif (direkt vom Scanner))
- Datenbanken (.sql)
- Abstracts im BIBTEX-Format (.bib)
- Webseiten (.htm, .html, .php)
- Inhalte von Patentdatenbanken (EPO, USPTO)
Ganz einfach: Dokumentlisten
Wenn es sich bei den Dokumenten nur um Patente handelt, ist es ganz einfach, zuerst einmal Listen mit unterschiedlichen Sortierungen zu erzeugen:
- Wer macht was wann?
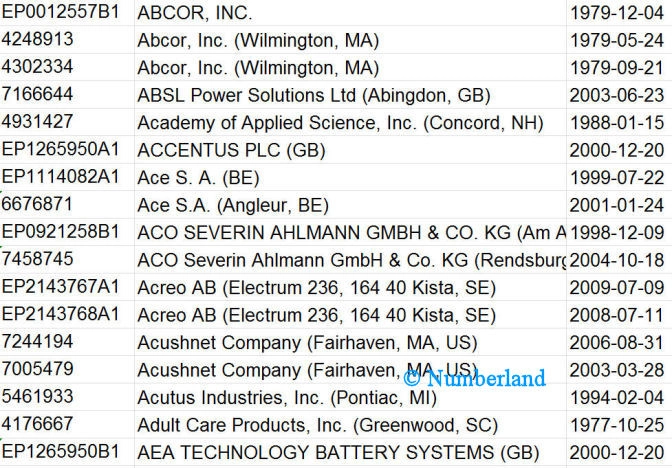
Bild 2: Liste von Patenten, alphabetisch sortiert nach Anmelder
Wann macht wer was?
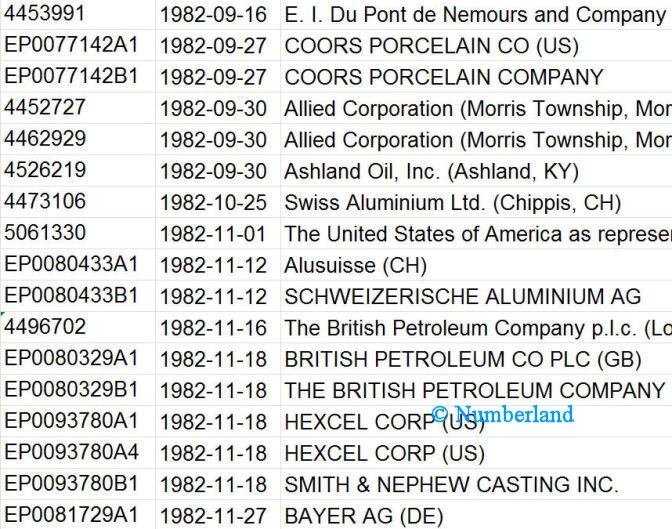
Bild 3: Liste von Patenten, sortiert nach Datum
Natürlich ist es auch möglich, solche Listen als verlinkte HTML-Dokumente zu gestalten, die z. B. direkte Verknüpfungen mit dem Basisdokument oder solchen Auswertungen enthalten, wie sie im weiteren Verlauf dargestellt sind.
Anders als z. B. bei einer klassischen Patentrecherche, bei der es darum geht, die Ergebnisliste möglichst klein zu halten (man muss ja schließlich alles lesen), kann die Dokumentkollektion (= der Korpus) einige tausend Dokumente umfassen. Dies ist möglich, weil durch die weitere Verarbeitung sowohl ein Gesamtüberblick, als auch Detailansichten für jeden beliebigen thematischen Schwerpunkt möglich sind.
Man hat also beides: den Überblick
- über einen Markt (=wer macht was)
- über denkbare Anwendungsmöglichkeiten (=wofür wird XYZ überhaupt benutzt)
- über das, was bereits realisiert, und das, was angedacht ist
um nur einige davon zu nennen.
Die Eigenschaftsmatrix entsteht
Im weiteren Verlauf der Analyse werden alle Dokumente des Korpus
- automatisch in einzelne Worte zerlegt, wobei
- bedeutungslose Worte entfernt, und
- alle Worte auf ihre Stammformen reduziert werden (hinter Automat, automatisch, automatischer, automatisches, etc. steckt immer der selbe Sinn). Anschließend wird für jedes Wort
- berechnet: wie groß ist die Bedeutung des Wortes sowohl für das einzelne Dokument, als auch für die gesamte Kollektion.
- Als Ergebnis entsteht eine Matrix, die so viele Zeilen enthält, wie Dokumente im Korpus vorhanden sind, und so viele Spalten (im Korpus) wie Worte besitzt. Jede Zelle der Matrix enthält die Bedeutung eines bestimmten Wortes für ein ausgesuchtes Dokument.
- Sowohl die Bedeutung der Dokumente, als auch die Bedeutung einzelner Worte wird als Zahl ausgedrückt, so dass man damit rechnen kann.
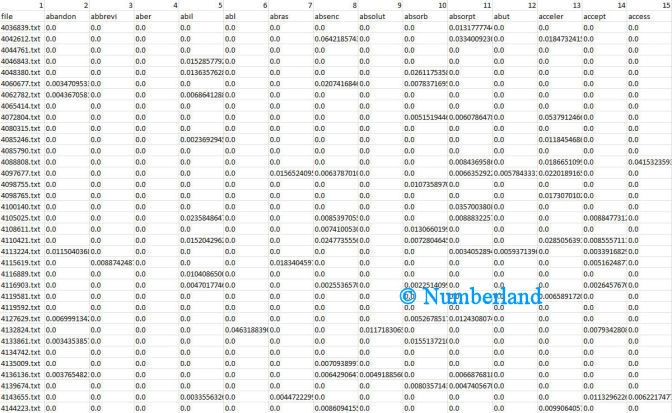
Bild 4: Eigenschaftsmatrix der Dokumentkollektion. Jede Zeile steht für ein Dokument, der Dokumentname (hier: Patentnummer) steht in der ersten Spalte. Ab der zweiten Spalte folgen so viele Spalten, wie Worte in der Dokumentkollektion enthalten sind, nachdem alle überflüssigen Worte entfernt worden sind (in diesem Beispiel ca. 3000). In den Zellen der Matrix steht ein Zahl als Maß für die relative Häufigkeit des betreffenden Wortes im Dokument.
Netzwerkanalysen
Mit Hilfe der Eingenschaftsmatrix ist es möglich, zu ermitteln, wie wichtig ein bestimmtes Thema für ein ausgewähltes Dokument ist (das Verfahren dazu läuft anders als das, was üblicherweise unter dem Begriff Suchmaschinenoptimierung (Search Engine Optimization - SEO) verstanden wird, weil in diesem Fall der reine Text analysiert wird, ohne dass Textattribute wie z. B. Überschriften, Seitennamen, Bildunterschriften, etc. berücksichtigt werden). Man berechnet - in unterschiedlicher Weise, das Verhältnis von Worthäufigkeit zu Artikellänge, um die Bedeutung eines Wortes für den Artikel zu erfahren.
Will man diese Information nicht für ein Dokument, sondern für eine Dokumentkollektion erfahren, ist dies im Prinzip mit Darstellungen wie in Bild 7 möglich: man zeigt die Häufigkeit eines ausgewählten Wortes für jedes einzelne Dokument der Kollektion. Schwieriger wird es jedoch, wenn die Bedeutung mehrerer Begriffe für viele Dokumente übersichtlich darzugestellt ist.
Abhilfe schafft in solchen Fällen ein Netzwekdiagramm. Sowohl Dokumente, als auch Themen sind als Punkte dargestellt, die durch Linien verbunden werden. Die Länge der Linie ist dabei ein Maß für die thematische Nähe. Kürzere Linien bedeuten also größere Nähe, und damit einen höheren Wert für die Worthäufigkeit in der Eigenschaftsmatrix. Die Punkte der Dokumente und Themen werden dabei so auf der Zeichenfläche verteilt, dass die "Entfernung" der Themen von einem bestimmten Dokument auf einen Blick ersichtlich ist. Bild 4a zeigt ein Beispiel mit drei Themen, und ca. 850 Dokumenten. Themenpunkte sind - entsprechend ihrer Bedeutung für die Dokumentkollektion - in passender Größe gezeigt.
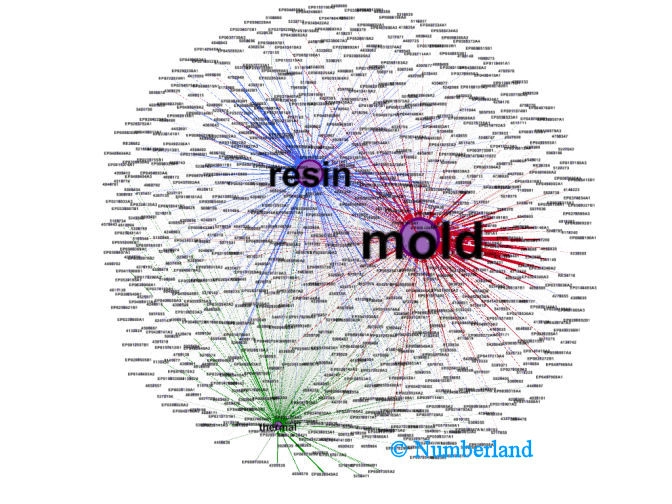
Bild 4a: Netzwerkdiagramm zur Darstellung der thematischen Entfernung von ca. 850 Patenten zu drei Themen (weitere Erklärung im Text).
Bild 4b zeigt die gleiche Dokumentkollektion, diesmal jedoch mit 20 Themen.

Bild 4b: wie Bild 4a, jedoch mit 20 Themen
Bild 4c zeigt einen Ausschnitt aus 4b, in dem nicht nur die Beschriftungen der Themen, sondern ebenso die Beschriftungen der Dokumente sichtbar werden.
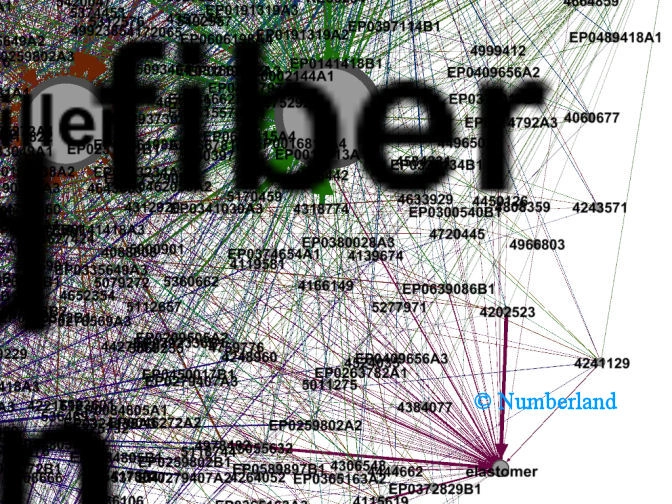
Bild 4c: Ausschnitt aus Bild 4b
Beispiele für einfache Grafiken
Der nächste Schritt könnte z. B. sein,
- darzustellen, wann wie viel zu einem Thema veröffentlicht worden ist.
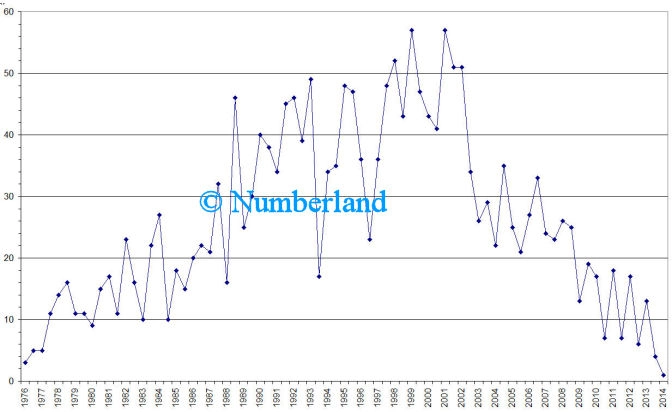
Bild 5: Anzahl der Patente zu einem bestimmten Thema pro Halbjahr
- sich ausgewählte Dokumente hinsichtlich ihres Wortprofils anzusehen
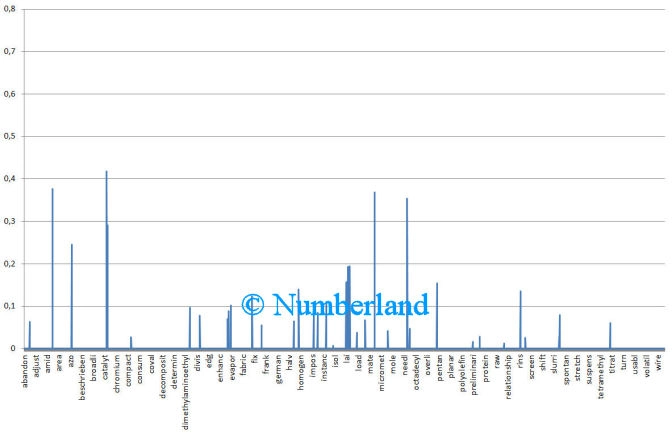
Bild 6: Wortprofil eines Dokument (=Darstellung der relativen Worthäufigkeit)
- die Worte der Häufigkeit nach zu sortieren, um einen Eindruck von Themenschwerpunkten zu bekommen
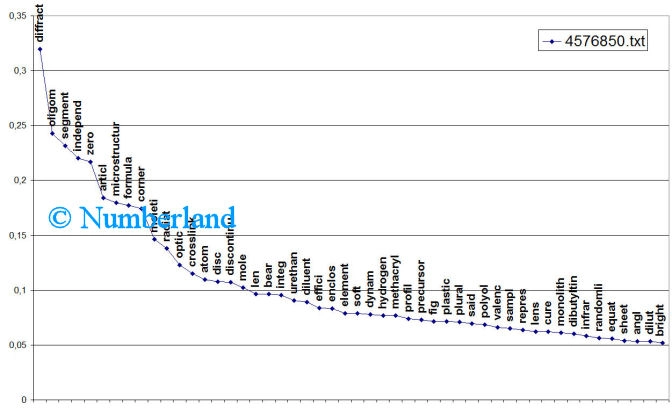
Bild 7: Die häufigsten Worte eines Dokuments, sortiert abfallend nach Häufigkeit
Clustern von Dokumenten
- oder die gesamte Dokumentkollektion in einzelne Cluster zu zerlegen
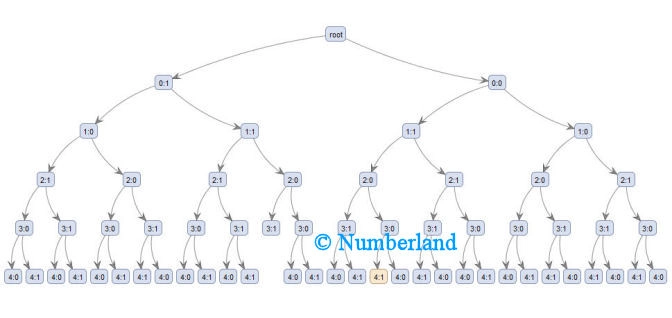
Bild 8: Zerlegung einer Dokumentkollektion in einzelne Cluster (hierarchisches Clustern)
Analysen, wie in den Bildern fünf, sechs und sieben dargestellt, können natürlich nicht nur für einzelne Dokumente, sondern auch für die ganze Kollektion oder jedes beliebige Cluster erstellt werden.
Wie funktioniert Clustern?
Bei der Zerlegung in Cluster werden Gruppen von Dokumenten so gebildet, dass die Lageabweichungen der Gruppenmitglieder vom gemeinsamen Schwerpunkt möglichst gering sind. Eine Darstellung des Vorgangs in zwei Dimensionen zeigt die nächste Abbildung:
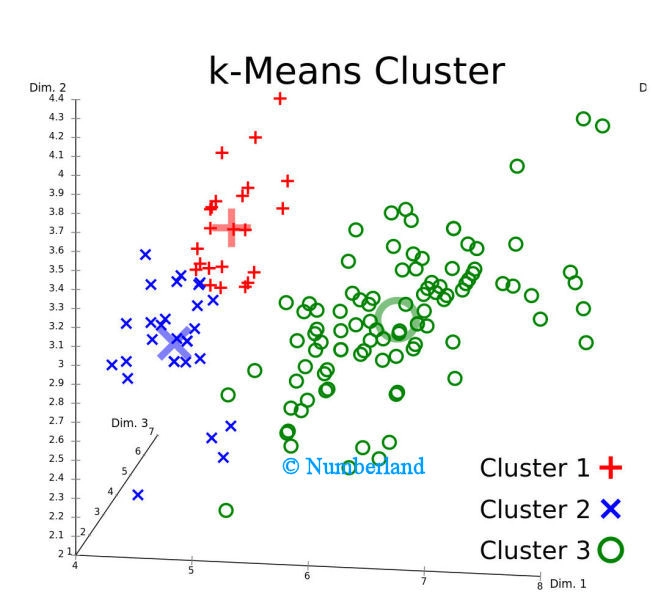
Bild 9: Gruppierung von einzelnen Werten in unterschiedliche Cluster nach der Methode K-Means.
Man erkennt einzelne Messwerte (rot, grün, blau), zusammen mit den Clusterschwerpunkten). Der Unterschied zur hier besprochenen Dokumentanalyse besteht jetzt nur darin, dass der Vorgang nicht im zweidimensionalen Raum, sondern z. B. im 3000-dimensionalen Raum stattfindet. Obwohl man sich einen solchen Raum nicht vorstellen kann, besteht aus mathematischer Sicht kein Unterschied: das Vorgehen ist das gleiche.
Um zu der Darstellung von Bild 8 zu gelangen, wurde das Verfahren mehrfach angewandt; es wurden zuerst eine Aufteilung in zwei Cluster vorgenommen, dann jedes der beiden Cluster wieder in zwei Cluster unterteilt, usw. (hierarchisches Clustern).
Selbstorganisierende Graphen
Die nächste Abbildung zeigt eine inhaltlich vergleichbare Darstellung der Clusterdarstellung mit Hilfe eines sogenannten „Selbstorganisierenden Graphen“, wobei auf der rechten Seite die Dokumente gelistet werden, die zu einem bestimmten Cluster gehören.
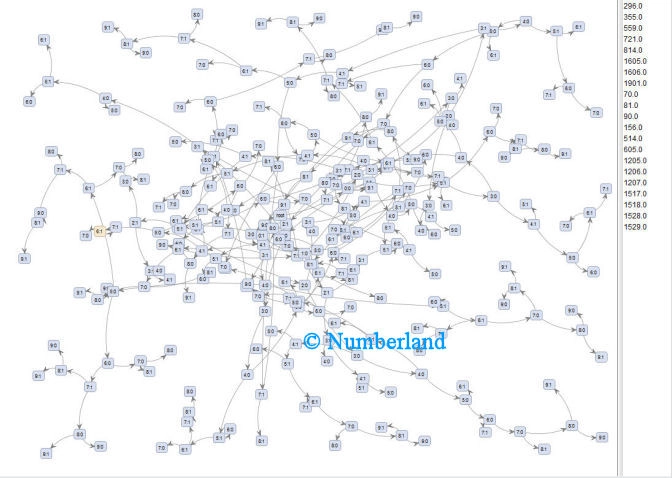
Bild 10: Darstellung der Zerlegung einer Dokumentkollektion in einzelne Cluster (wie Bild 9), jedoch mit Hilfe eines selbstorganisierenden Graphen.
Bild 11 zeigt das Ergebnis wie in Bild 10, jedoch mit einem Graphen anderen Typs.
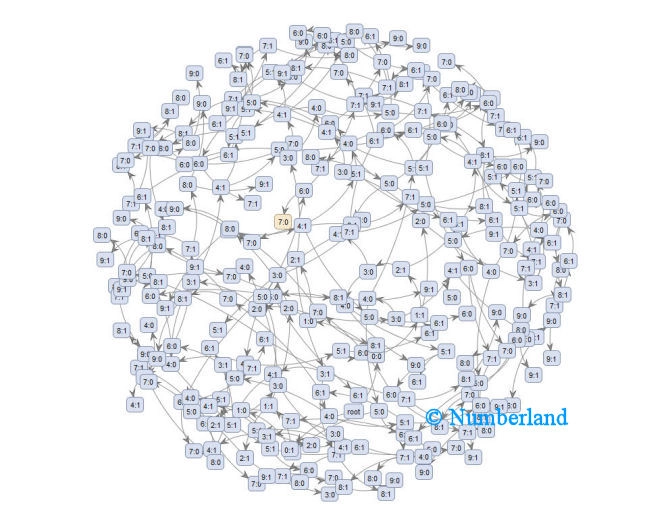
Bild 11: wie Bild 10, jedoch mit einem Graphen anderen Typs
Clustern II: Schwerpunkteverschiebung als Funktion der Zeit
Natürlich besteht auch die Möglichkeit, inhaltliche Schwerpunkt analog zu Bild 9 für jedes Jahr zu berechnen, und die Lage der Schwerpunkte im Verlauf der Zeit darzustellen (=wie verschiebt sich ein inhaltlicher Schwerpunkt mit der Zeit).
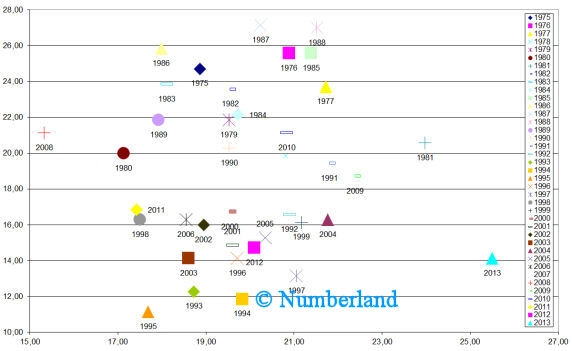
Bild 12: Für alle Dokumente mit einem Veröffentlichungsdatum in einem bestimmten Jahr wird die Lage des thematischen Schwerpunkts berechnet und in einem Koordinatensystem eingezeichnet. Auf diese Weise entsteht durch Verbinden der Punkte in chronologischer Reihenfolge ein "thematischer Pfad", der zeigt, welche inhaltlichen Verschiebungen von Jahr zu Jahr aufgetreten sind.
Was versteht man unter dem Begriff "Zusammenfassen"?
Zusammenfassen bedeutet, die wesentlichen Konzepte eines Textes in wenigen Abschnitten zu konzentrieren, und alles unwesentliche weg zu lassen. Im Extremfall kann eine Zusammenfassung sogar nur aus den wichtigsten Worten bestehen.
Während die Aufgabe des Zusammenfassens von Texten in der Vergangenheit nur durch Menschen durchgeführt werden konnte, sind Computeralgorithmen in der Zwischenzeit gut genug, um vergleichbare Ergebnisse zu liefern.
Zusammenfassen - Finden, was Sie bisher nicht wissen
Ist man bis hierher gekommen, sind die Kenntnisse über die Dokumentkollektion bereits deutlich umfangreicher als am Anfang der Untersuchung. Es wäre zum Beispiel aber noch wichtig, nicht nur zu wissen, welche Cluster vorhanden sind, und welche Dokumente zu den einzelnen Clustern gehören, sondern welche Themenkomplexe die einzelnen Clustern bestimmen.
Während man sonst nur suchen kann, was man kennt, kann man auf diese Art auch das finden, was man nicht kennt ...
Eine derartige Analyse zeigt Bild 13. Hier ist eine Dokumentkollektion wieder in mehrere Cluster unterteilt (linke Seite), wobei die Clustergröße durch die Kreisgröße visualisiert wird. Auf der rechten Seite ist für ein markiertes Cluster zu sehen, welche Begriffe in diesem Cluster besonders häufig sind (rote Balken). Die blaugrauen Balken zeigen die Häufigkeit der Begriffe in der gesamten Kollektion
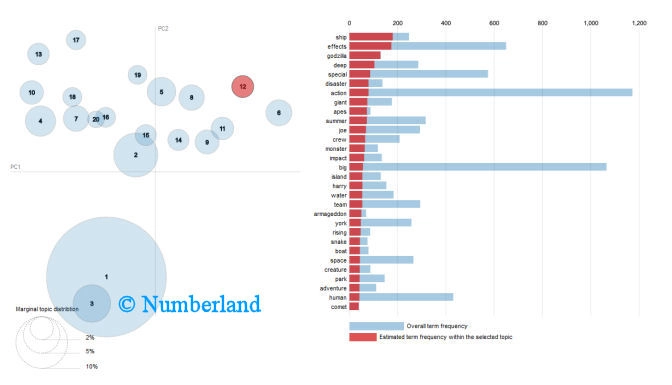
Bild 13: Erklärung im Text
Zusammenfassen mit "Topic Models"

Bild 13b: Mit Hilfe dieser Liste aus 25 Themen, mit jeweils 20 Schlüsselworten wird eine Kollektion von ca. 450 Patenten erschlossen.
Anstatt Dokumente in Cluster zu gruppieren, und anschließend zu ermitteln, welche Inhalte in welchen Clustern dominieren, kann auch ein anderer Weg beschritten werden.
Man ermittelt, welche Themenkomplexe in der gesamten Dokumentkollektion vorhanden sind, und ordnet dann die Dokumente der Kollektion den Themen zu. Obwohl auf den ersten Blick kein gravierender Unterschied zum zuerst genannten Verfahren besteht, ist dieser Unterschied jedoch serwohl vorhanden.
Bei der Zuordnung von Dokumenten zu Clustern wird davon ausgegangen, dass ein bestimmtes Dokument eindeutig einem bestimmten Cluster zugewiesen werden kann. Im Gegensatz dazu ist das umgekehrte Verfahren in der Lage, ein Dokument als aus mehreren Abschnitten bestehend aufzufassen, die ihrerseits zu unterschiedlichen Themenkomplexen gehören können.
Das nachfolgende Beispiel zeigt das Ergebnis einer Analyse, bei der ca. 450 Patente in 25 Themenkomplexe zerlegt worden sind, wobei jedes Thema durch max. 20 Stichworte repräsentiert wird.
Klickt man ein Thema an, erhält man eine Liste der zugehörigen Dokumente, absteigend sortiert nach der Anzahl der Worte des Themas, die im Dokument enthalten sind.
Weitere Detailansichten mit einfachen Grafiken II
Natürlich kann man auch die Frage stellen, mit welcher Häufigkeit ein bestimmter Begriff in unterschiedlichen Clustern vorhanden ist. Die Antwort auf eine solche Frage wird in Bild 14 gezeigt.
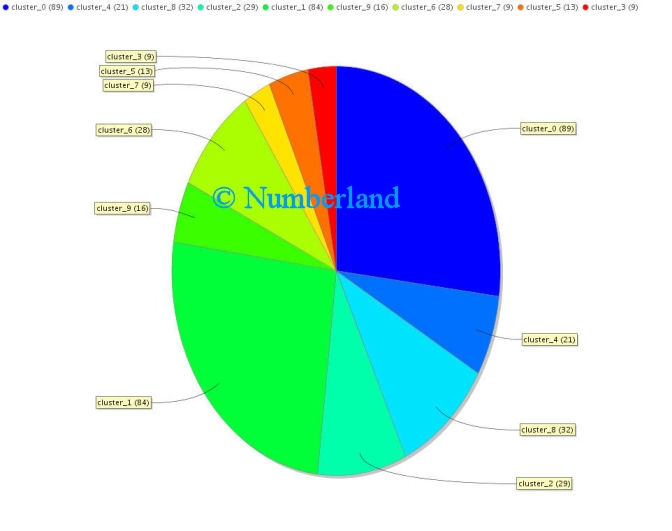
Bild 14: Darstellung der Häufigkeit eines Begriffs in unterschiedlichen Clustern
Bild 15 zeigt – als weitere Variante – die Bedeutung mehrerer Begriffe für die einzelnen Dokumente in unterschiedlichen Clustern.
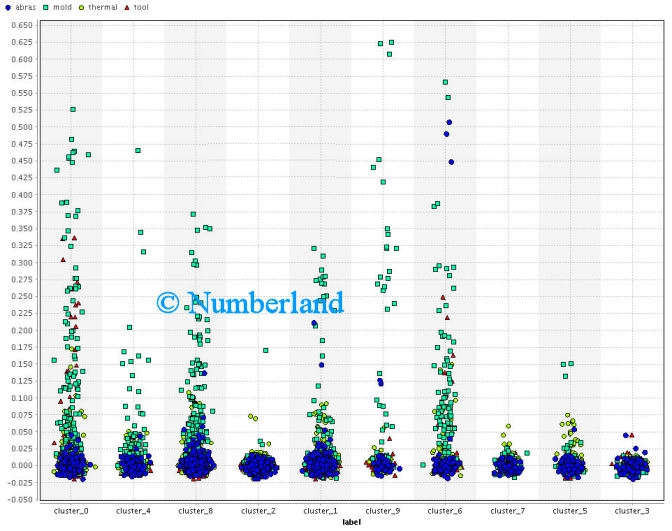
Bild 15: Bedeutung unterschiedlicher Begriffe (kodiert durch Punktfarben, vgl. oben links) für die Dokumente in unterschiedlichen Clustern
Im nächsten Bild sieht man, mit welcher inhaltlichen Bedeutung ein bestimmter Begriff in einem Dokument gemessen wird (erste Zahl), und in wie vielen Fälle dies so ist (zweite Zahl in Klammern).
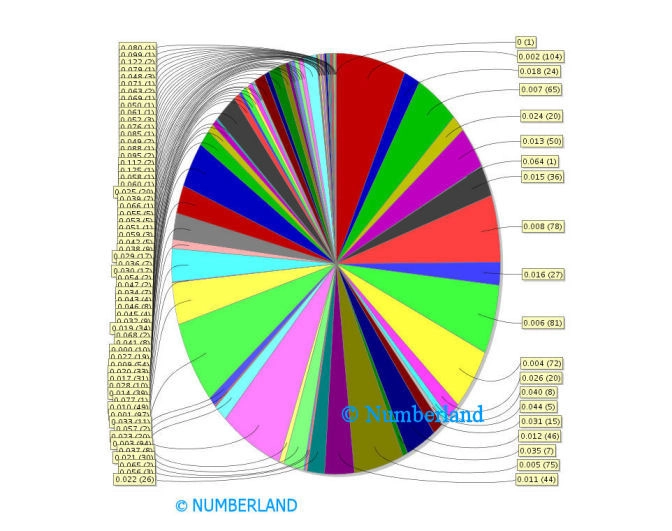
Bild 16: Welche inhaltliche Bedeutung hat ein bestimmter Begriff in einem Dokument, (erste Zahl), und in wie vielen Fälle ist dies so (zweite Zahl in Klammern).
Eine etwas andere Art der Darstellung zeigt Bild 17. Hier sind unterschiedlich breite Verteilungskurven gezeigt, wobei jede Kurve die Verteilung eines Begriffes in einem Cluster darstellt. Eine enge Verteilungskurve bedeutet, dass der Begriff in allen Dokumenten eines Clustern mit ungefähr gleicher Häufigkeit zu finden ist. Eine breite Verteilungskurve meint hingegen, die Begriffshäufigkeit in den einzelnen Dokumenten des Clusters variiert über einen weiten Bereich (in Bild 16 variiert die Begriffshäufigkeit zwischen 0,002 und 0,122, also eher über einen weiten Bereich).
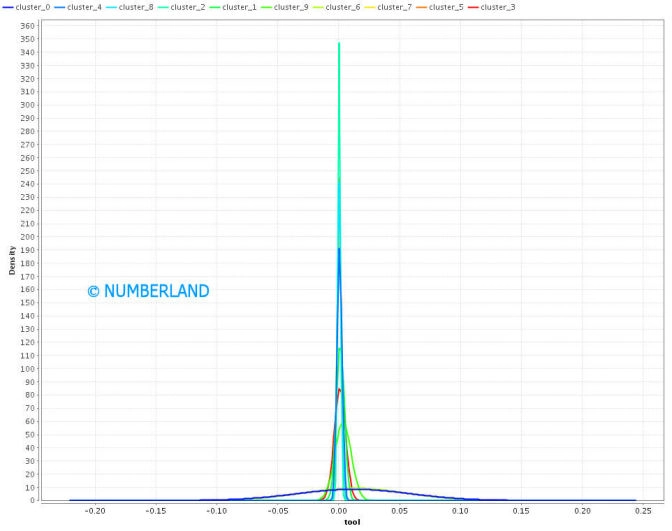
Bild 17: Verteilungskurve eines Begriffs in unterschiedlichen Clustern (Erklärung siehe Text).
Was bedeutet "Korrelation"?
Was versteht man unter dem Begriff Korrelation?
Korrelation bedeutet Wechselbeziehung und beschreibt einen Zusammenhang zwischen zwei oder mehreren Merkmalen, Ereignissen, Zuständen oder Funktionen. Positive Korrelation bedeutet, dass bei der Vergrößerung des Wertes eines Merkmals auch der Wert des damit korrelierten Merkmals ansteigt. Für negative Korrelation gilt das Gegenteil.
Einfache Korrelationen
Bild 18 zeigt dann die Korrelation von drei Begriffen in den ca. 2000 Einzeldokumenten von 10 Clustern. X-Achse: Cluster, Position auf der Y-Achse: Bedeutung des ersten Begriffes, Kreisgröße: Bedeutung des zweiten Begriffes, Farbe: Bedeutung des dritten Begriffes.
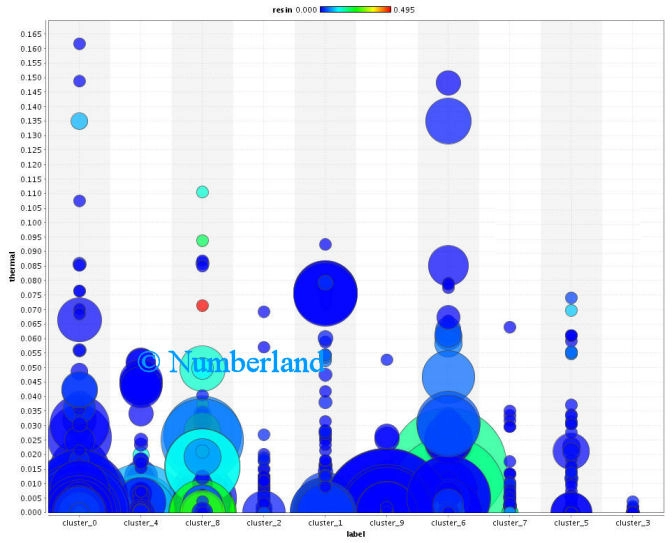
Bild 18: Korrelation von drei unterschiedlichen Begriffen in 10 Clustern, bestehend aus ca. 2000 Dokumenten (Erklärung siehe Text).
Welche Korrelationen sind überhaupt vorhanden?
Die Bedeutung von Korrelation hat man unter Umständen zum Beispiel im Zusammenhang von Warenkorbanalysen vielleicht bereits gehört (nach dem Motto: eine Frau, die gleichzeitig Schokolade und Gurken kauft, ist wahrscheinlich schwanger). Solche Korrelationen zu finden ist natürlich auch für Dokumentanalysen ausgesprochen interessant.

Bild 19: Alle in einer Dokumentkollektion gefundenen Korrelationen (=Assoziationen).
Korrelationen zum Begriff "Temperatur"
Bild 20 zeigt – herausgegriffen aus allen Korrelationen aus Bild 19 – die Korrelationen in Zusammenhang mit einem ausgewählten Begriff (d. h., welche Worten treten immer wieder im Zusammenhang mit einem ausgewählten Wort auf).
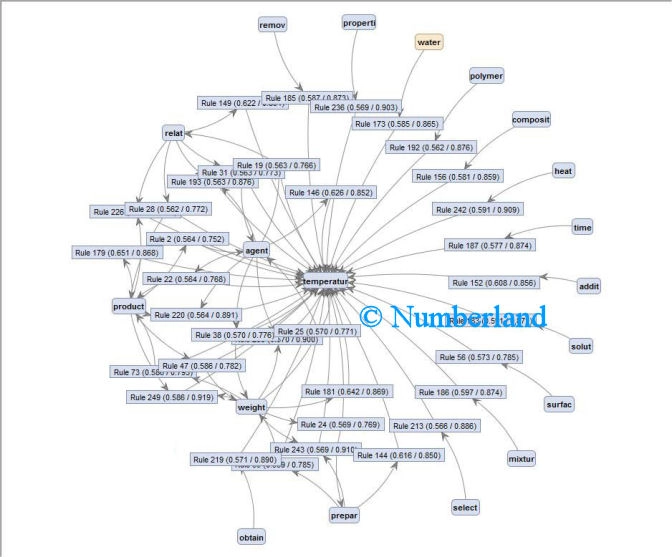
Bild 20: Korrelationen im Zusammenhang mit dem Begriff "Temperatur".
Clustern und Korrelationen live
Bild 21 schließlich zeigt die Oberfläche einer Suchmaske. Zusammen mit einem Volltextindex über alle Dokumente ist es so möglich, im Zusammenhang mit den bisher vorgestellten Untersuchungen interaktiv in allen Dokumenten zu suchen. Die Ergebnisse der Suche erhält man
- als normale Trefferliste angezeigt (1),
- automatisch in Untergruppen eingeteilt (2), wobei
- der inhaltliche Zusammenhang zwischen den Gruppen (=Cluster) grafisch dargestellt wird (3).
- Die Teilbilder (4) und (5) schließlich zeigen eine Darstellung der Gruppengröße auf zwei unterschiedliche Weisen.
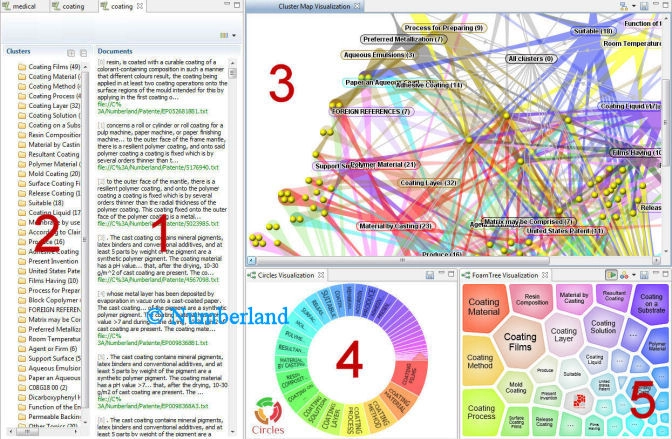
Bild 21: Suchmaske, die den interaktiven Zugriff auf eine Kollektion von ca. 2000 Patenten ermöglicht (Erklärung siehe Text).